Language models are trained on the internet. Physical AI has to generate its training data one trajectory at a time.
Physical AI has no internet
When people talk about why language models worked, they usually point to scale: bigger models, more compute, better optimizers. The truth is that the internet did most of the work in creating that scale. By the time GPT-3 arrived, decades of human writing had already been digitized, indexed, and made cheaply available. The training data wasn’t free, but it existed.
The systems we now increasingly call physical AI, which includes robots that grasp, vehicles that drive, drones that inspect, and machines that manipulate, need to learn from streams of multimodal sensorimotor data. This data is generated only when something physical actually moves through the world. There is no archive of a billion robot arms picking up a billion objects waiting to be scraped. There is no Common Crawl of contact-rich manipulation.
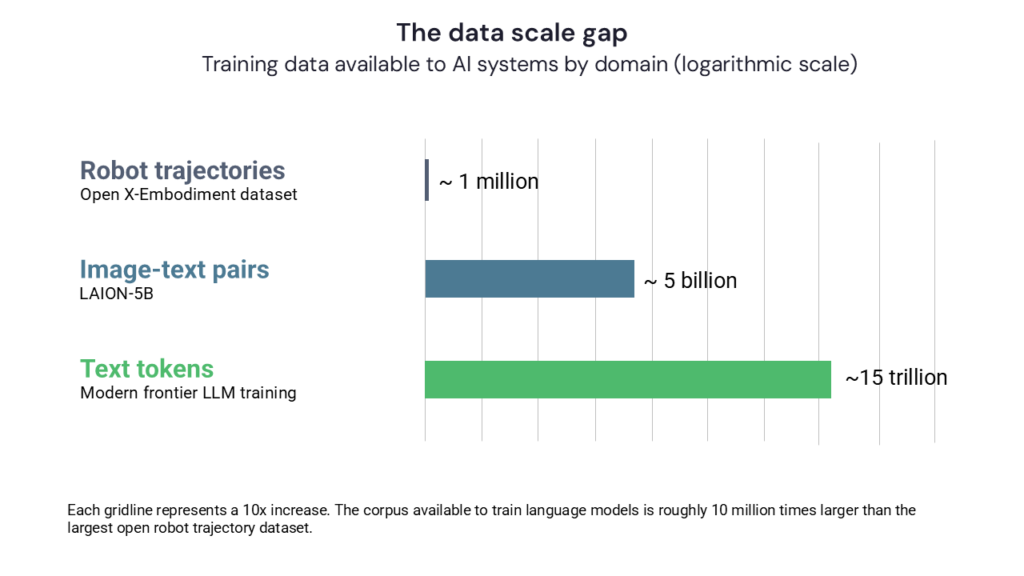
The numbers make the gap concrete. Open X-Embodiment, the largest open dataset of real robot trajectories, pools roughly one million episodes across 22 robot platforms and 60 source datasets contributed by more than 30 research labs. That is a heroic effort and the closest thing the field has to a shared corpus. For comparison, modern language models are trained on corpora measured in trillions of tokens scraped from the open web. The two scales are not in the same neighborhood; they are separated by roughly seven orders of magnitude.
The cost of making physical data
The making of this data is expensive. You need hardware (a real robot, or a fleet of them). You need environments (warehouses, kitchens, surgical suites, orchards). You need supervision (humans labeling, demonstrating, teleoperating, correcting). And you need time. You can’t speed up gravity, and you can’t batch-process a robot’s morning the way you can batch-process a corpus of tokens.
The unit cost of measuring a trajectory of a robot arm through space or any other physical-world activity is many orders of magnitude higher than the unit cost of a useful sentence. The common practice of creating this data is referred to as teleoperations, whereby human operators control the robot through countless training runs, capturing data on many successful and failed executions of a task. Recent industry estimates put high-quality teleoperation data at roughly $120 per operator-hour as of early 2026, down from around $340/hour two years earlier. This is real progress, but still expensive when you consider that most manipulation tasks require somewhere between 300 and 1,200 demonstrations to train a useful policy. That puts the data budget for a single new task in the range of $50,000 to $150,000, before you have taken the first step toward having a product that could do something useful. And one hour of robot training data still requires roughly one hour of skilled human operation, because you cannot speed up the demonstrations any more than you can speed up the robot.
Tesla’s Autopilot fleet, Waymo’s driving operations, and the various humanoid companies racing to put robots in warehouses are all, at root, very expensive data collection programs with products attached. Waymo crossed 200 million fully autonomous miles in early 2026, a milestone that took more than fifteen years of methodical operations and billions of dollars of capital to accumulate. The hardware, the workforce, and the operations are not incidental to the AI; they are how the AI is fed.
A Higher Bar
Because of what is at stake, model and performance accuracy requirements for physical AI are substantially higher than what is acceptable for chatbots and generative AI. A floor-cleaning robot in a hospital corridor that fails to recognize a patient’s IV pole can pull out a line. A delivery robot that misreads a curb cut can roll into traffic. Because the system is operating in the real world, often around real people, the bar for getting everything right is much higher than for software that lives behind a screen. A chatbot judged acceptable at 95% task success would be a workplace hazard as a robot. Insurers, OSHA, and the lawyers who follow them are going to expect failure rates orders of magnitude lower, demonstrated across millions of operating hours, before they sign off on broad deployment.
This pre-deployment reliability problem compounds the data problem. Hitting the reliability bar requires data not just on the routine cases, such as the standard pick, the typical aisle, the textbook obstacle, but on the long tail of rare and awkward conditions where systems actually fail. So the data requirement is not “enough trajectories to do the job.” Instead, it is “enough trajectories to do the job, plus enough rare-event coverage to be safe doing it.” For most physical AI applications, the rare-event dataset is harder to acquire and even more expensive than the routine one.
The commercial gate
Because data collection is so expensive, it only makes sense for problems large enough to justify the investment. Self-driving cars get the data because the addressable market is in the trillions of dollars. Industrial pick-and-place gets data because the warehouse and logistics market is enormous and operationally homogeneous. Surgical robotics gets data because procedures are billable at very high rates and a few percentage points of better outcomes translate into real money.
The challenge is that most observers believe the physical world is a long tail situation. While there are certain task and behaviors that underpin billion or even trillion dollar markets, the vast majority of tasks do not. Take for example the robot that could prune grapevines, or restock a small pharmacy, or repair a broken washing machine, or help an elderly person stand up from. Each of these is a real problem and a real market, but potentially not a market large enough to justify millions of dollars of bespoke data collection.
This is the chicken-and-egg of physical AI. In software, you can ship a v0 with three engineers and a weekend. In physical AI, your v0 might require a year of teleoperation across twenty robots in five facilities before the model can do anything useful at all.
Without data you cannot build the application, and without the application there is no reason to collect the data. This loop is harder to break than in almost any other area of technology.
Two verticals, two destinies
Here are two markets that clearly illustrate the Physical AI data challenge.
Surgical robotics is data-rich. Intuitive Surgical’s da Vinci platform has performed roughly 17 million procedures cumulatively, with about 2.7 million in 2024 alone, across more than 10,000 installed systems worldwide. Each procedure generates hours of video, instrument motion, and force data, recorded on a platform whose installed base supports a company with roughly $10 billion in annual revenue. The market structure does the data collection for you: high-margin procedures, long-lived hardware, a dominant operator with strong incentives to instrument everything. Surgical AI doesn’t have a data problem so much as a data-access and regulatory problem, which is a very different thing.
Specialty agriculture is data-starved. The economics of demand are real — specialty crops (fruits, berries, leafy greens, vines, nuts) account for around 40% of U.S. farm cash expenses on labor, roughly three times the rate of row crops, and the agricultural robotics market is forecast to reach the tens of billions by the early 2030s. Capital is showing up: more than $1 billion went into harvesting and weeding startups between 2022 and 2025. But the data is fragmented in ways that surgical data is not. Every crop has different morphology, different ripeness cues, different damage tolerances. Farms can have different row spacing, soil, and microclimate. Recent literature reviews of AI in agriculture note that academic and commercial datasets remain heavily concentrated on maize, rice, and wheat, while berries, leafy greens, and tropical fruits (the high-labor specialty crops where robotics would matter most) are persistently underserved, due to scarce open datasets, high variability in plant morphology, and limited commercial incentives driving large-scale data collection.
Three potential solutions
There are three main attempts to break out of this trap, and the future of physical AI depends upon which, if any, work at scale.
The field is pursuing three possible solutions to the training data problem — simulation, foundation models that transfer across tasks, and shared data infrastructure — but none has yet proven sufficient on its own.
The first is simulation. If you can train robots in a simulated world, you can generate trajectories cheaply and in parallel. Sim-to-real has gotten genuinely good for some problems, and locomotion in particular has benefited enormously from massively parallel simulated rollouts. But the sim-to-real gap grows fast as you move from physics that’s well-modeled (rigid body dynamics) to physics that isn’t (cloth, fluids, granular materials, deformable objects, contact-rich manipulation). For most of the long tail of useful tasks, simulation is part of the answer but not the whole answer.
The second is foundation models for robotics. The bet here is that if you train one big model on a large enough mixture of robotic data (possibly combined with internet video, possibly combined with language), you get general physical capability that transfers to new tasks with minimal additional data. If this works, it inverts the economics: instead of every application paying for its own data from scratch, applications draw from a shared substrate. The grapevine-pruning robot doesn’t need ten million pruning demonstrations; it needs a thousand, on top of a base model that already understands branches and shears and the general shape of the world.
The capital behind this bet is now serious. Physical Intelligence has raised over $1.1 billion at a roughly $5.6 billion valuation. Skild AI has raised about $1.8 billion at a $14 billion valuation. Figure raised over a billion in late 2025 at a reported $39 billion valuation. These are not exploratory grants; they are bets, in aggregate worth tens of billions of dollars, that one or more general-purpose physical intelligence models will hold up at scale.
The third is shared data infrastructure. By this we mean pen datasets, standardized teleoperation rigs, data marketplaces, consortia, and government-funded collection. Efforts like Open X-Embodiment have pointed in this direction. The challenge is that physical data is much less portable than text. Different robots have different morphologies, different sensors, different action spaces. A grasp recorded on one arm doesn’t necessarily apply to another. Some of this can be normalized; some of it probably can’t.
None of these is yet a clear win. Which means we are in a strange interim where the future of dozens of plausibly useful physical AI applications depends on bets being made right now in a handful of well-funded labs about whether one of these approaches will work.
Uncertainty and The Training Data Solution
It is entirely possible that physical AI develops mostly in markets large enough to fund their own data, and that everything else stays out of reach for a long time, and that we end up with a kind of permanent two-tier landscape where driving and warehouse manipulation get solved while elder care and small-scale agriculture and home repair don’t. We arrive at this outcome not because the technical problems are harder but because it doesn’t pay to teach the machine.
It is also possible that one of the foundation-model bets pays off and the long tail unlocks suddenly, the way image generation went from impossible to commodity in about three years.
3It’s even possible that some combination of consumer hardware eventually creates a real corpus of household physical interaction data — the way smartphones, almost incidentally, created corpora of photos and locations and movement patterns that nobody had planned to assemble.
The bottleneck for the next phase of AI is unlikely to be compute. It is more likely to be the cost of collecting the physical data needed to train these systems.
Yet another possibility is that a solution will present itself that we have not yet considered yet. The scale of the problem and opportunity means there is no shortage of intellectual and financial capital being dedicated to a solution.
Is there a chance that there is no solution, or that the solution is more than a decade away? I think that is unlikely.
What I’m most confident about is that the answer isn’t “more compute.” The bottleneck has shifted. For the past several years of AI progress, the central question has often been “can we scale this up?” For physical AI, the central question is “where does the data come from, and who pays for it?”
